El gran impacto de AlexNet
Mucho se habla de las CNN, pero ¿qué impacto tuvo la clasificación de imágenes a gran escala tras AlexNet e ImageNet?

Juanes Idrobo
18 de diciembre de 2025
Durante muchos años, la clasificación automática de imágenes fue uno de los problemas más complejos de la visión por computadora. Antes de 2012, los enfoques dominantes combinaban descriptores diseñados manualmente (como SIFT o HOG) con clasificadores tradicionales (por ejemplo, máquinas de soporte vectorial). Aunque estos métodos lograban buenos resultados, su desempeño se estancaba y dependía fuertemente de la ingeniería de características.
Este panorama cambió con la aparición del artículo “ImageNet Classification with Deep Convolutional Neural Networks” publicado por Alex Krizhevsky, Ilya Sutskever y Geoffrey E. Hinton. Allí demostraron que una red neuronal convolucional profunda, entrenada end-to-end sobre millones de imágenes, podía superar ampliamente a los enfoques existentes en el desafío ImageNet.
La arquitectura —posteriormente conocida como AlexNet— no solo ganó la competencia ILSVRC 2012 con una diferencia sin precedentes, sino que también marcó el inicio de una nueva era: el aprendizaje profundo aplicado a visión por computadora.
Arquitectura innovadora de AlexNet
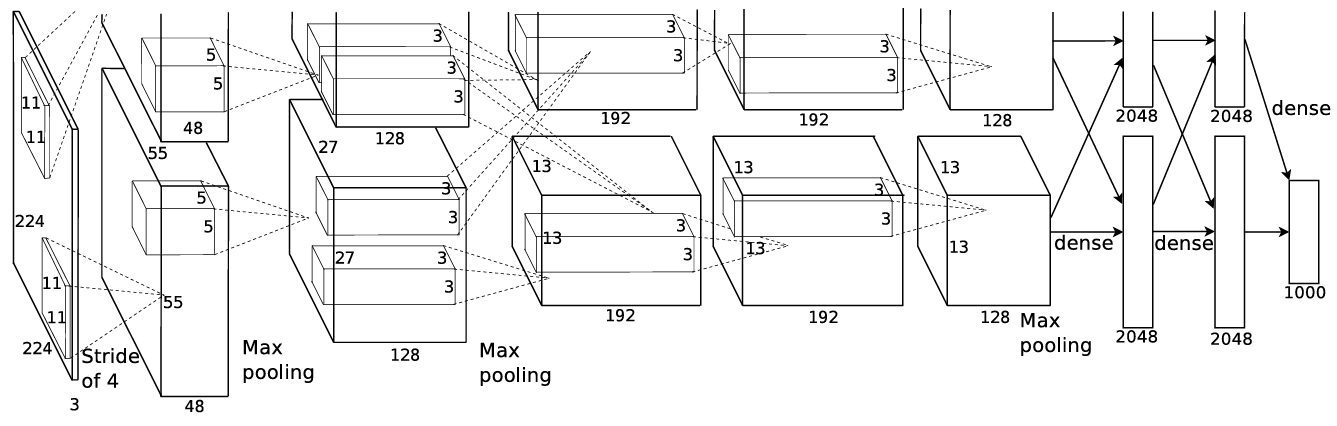
Clasificar ~1.2 millones de imágenes de alta resolución requería un modelo con gran capacidad de aprendizaje. AlexNet consta de 8 capas con parámetros: 5 convolucionales y 3 totalmente conectadas.
ReLU: entrenamiento mucho más rápido
Una de las innovaciones más relevantes fue el uso de unidades lineales rectificadas (ReLU) en lugar de funciones de activación tradicionales como tanh.
ReLU(x)=max(0,x)
El beneficio principal fue acelerar el entrenamiento: en el artículo se menciona que, en CIFAR-10, una red de cuatro capas con ReLU alcanza ~25% de error de entrenamiento aproximadamente 6× más rápido que una equivalente con tanh.
Paralelización en múltiples GPUs
Otra característica clave fue la paralelización en dos GPUs, ya que el tamaño del modelo excedía la memoria de una sola tarjeta (en ese momento usaron GTX 580 de 3 GB). Para lograrlo, dividieron la red en dos partes y conectaron ciertas capas de manera restringida entre GPUs.
Este esquema permitió entrenar modelos más grandes y, según el paper, produjo mejoras de desempeño (reducciones en top-1 y top-5) respecto a variantes sin esta estrategia.
Normalización de respuesta local (LRN)
AlexNet también popularizó la Local Response Normalization (LRN), aplicada después de ReLU en algunas capas. La motivación se inspira en la idea de inhibición lateral en sistemas biológicos. En el artículo se reporta que la LRN contribuyó a la generalización, reduciendo el error top-1 y top-5 en ciertos experimentos comparativos.
Tamaños y flujo de la arquitectura
A nivel general, la primera capa convolucional filtra una imagen de entrada de 224×224×3 con 96 kernels de 11×11×3. En el paper también se menciona que algunas capas (como 2, 4 y 5) se conectaban únicamente con kernels de la capa anterior dentro de la misma GPU, como parte del esquema de paralelización.
La arquitectura completa (con número de neuronas y capas) se muestra a continuación. Es interesante notar cómo el número de activaciones disminuye progresivamente hasta llegar a 1000 neuronas, correspondientes a las 1000 clases de ImageNet.
Técnicas de regularización y control del overfitting en AlexNet
El artículo explica que, incluso con una restricción fuerte en la asignación imagen-etiqueta, el modelo aún tendía al overfitting, por lo que aplicaron dos técnicas principales para mitigarlo.
1) Aumento de datos (data augmentation)
Se amplió el dataset mediante transformaciones que preservan la etiqueta, como:
- Traslaciones y reflejos horizontales
- Extracción de parches aleatorios de 224×224 a partir de imágenes de 256×256
- Alteración de intensidades RGB usando PCA (para capturar cierta invariancia frente a cambios de iluminación)
Este enfoque se volvió un estándar en visión por computadora.
2) Dropout en capas totalmente conectadas
La segunda técnica fue dropout en las dos primeras capas totalmente conectadas. Durante el entrenamiento, dropout pone en cero la salida de cada neurona con probabilidad 0.5, lo que reduce la co-adaptación y favorece representaciones más robustas.
El impacto en estudios posteriores y en la industria
AlexNet fue un punto de inflexión en la historia del deep learning. Mostró, de forma contundente, que las CNN profundas eran viables y superiores para tareas reales en visión por computadora. Después de 2012, el interés por redes profundas se disparó: muchas conferencias y trabajos que antes evitaban redes neuronales comenzaron a adoptarlas como estándar.
Arquitecturas posteriores como VGGNet y GoogLeNet/Inception (2014) tomaron y extendieron ideas clave popularizadas por AlexNet, como el uso sistemático de ReLU y el entrenamiento intensivo con aceleración por GPU.
Además, AlexNet consolidó la importancia del preentrenamiento a gran escala: el transfer learning con modelos entrenados en ImageNet se convirtió en una práctica común para múltiples tareas (clasificación, detección, segmentación, etc.).
En la industria, el éxito de AlexNet ayudó a validar el uso de GPUs como infraestructura central para IA. Este cambio aceleró el desarrollo de herramientas y bibliotecas de cómputo profundo (como cuDNN) y empujó a grandes compañías a construir productos basados en visión por computadora a gran escala (búsqueda visual, organización de fotos, etiquetado automático, asistencia a la conducción, etc.).
Lo que dejó AlexNet es de remarcar:
- Su artículo de NeurIPS 2012 está entre los más citados en la historia de la IA.
- En ILSVRC 2012, AlexNet logró ~15.3% de top-5 error (≈84.7% de top-5 accuracy), frente a ~26.2% del segundo lugar, marcando un salto enorme en rendimiento.
- Su influencia se refleja en el diseño de redes modernas y en su presencia conceptual en frameworks como PyTorch y TensorFlow.
Limitaciones y legado de AlexNet
A pesar de su impacto transformador, AlexNet presenta limitaciones claras desde la perspectiva moderna. Tiene un gran número de parámetros, especialmente en las capas totalmente conectadas, lo que implica alto consumo de memoria y menor eficiencia computacional comparado con modelos posteriores.
Además, dependía de grandes volúmenes de datos etiquetados y de recursos computacionales especializados, lo que en su momento restringía su adopción fuera de ciertos entornos de investigación. Técnicas como LRN, importantes en AlexNet, fueron reemplazadas más adelante por alternativas más estables y eficientes como Batch Normalization.
Aun así, AlexNet puede verse como el punto de partida del aprendizaje profundo moderno en visión por computadora: el modelo que demostró, a escala y con resultados contundentes, que entrenar redes profundas end-to-end sobre datos masivos no solo era posible, sino superior.
En resumen
El impacto académico de AlexNet, su papel en la mejora de benchmarks y su influencia directa en herramientas y arquitecturas modernas evidencian un cambio de era: a partir de 2012, el deep learning dejó de ser una promesa y se convirtió en el estándar para gran parte de la visión por computadora.
¿Te gustó este artículo? ¡Compártelo!
